Assistënza IA por le ladin scrit alpha
Mioré o se lascé dé formulaziuns alternatives por tesć ladins.
Frases da vignidé
Traduziun automatica por le ladin
Poscibilités nöies da adoré y promöie le lingaz ladin scrit.
Tl cheder de n proiet de colauraziun danter l'Université da Desproch y l'Istitut Ladin Micurá de Rü é nosta inrescida dedicada al svilup de n sistem inovatif de traduziun automatica por le lingaz ladin.
Le lingaz ladin é caraterisé da süa gran varieté: al müda da valada a valada. Les variantes prinzipales é chëres dla Val Badia, de Gherdëna, Fascia, Ampëz y Fodom. Chëstes variantes rapresentëia na desfida particolara, deache vignöna mëss gní tratada por so cunt. Nosc laur se conzentrëia te chësc momënt sön la varianta dla Val Badia. I svilupun soluziuns sön mosöra por chësta varianta, cun l'obietif da adoté dedô chëres plü efiziëntes por les atres variantes dl lingaz. Tres chësc laur porvunse da cherié n sistem de traduziun che respetëies y valorisëies la varieté linguistica y culturala straordinara dl lingaz ladin.
Na inrescida ampla
De regola adora i sistems de traduziun na gran cuantité de tesć por podëi funzioné bun. La desponibilité de n numer limité de tesć ch’an á indere ti mëndri lingac ne basta nia por i algoritms d’aldedaincö. Ti ultims agn él gnü svilupé de plü soluziuns por superé la desponibilité limitada de dac o por adoré i tesć che é a desposiziun te na manira plü inteliënta.
Implü él cun la publicaziun de ChatGPT y d'atri "Large Language Models" (LLMs) gnü daurí n setur de inrescida dla traduziun automatica daldöt nü. Chisc gragn modei linguistics á na comprenjiun imprescionanta dl lingaz y an pó i adaté a problems nüs cun püc ejëmpli. En combinaziun cun les soluziuns che é bele gnüdes svilupades, podess chëstes capazités sëgn ince gní adorades por svilupé sistems de traduziun automatica por lingac de mendranza.
Contribut
Le svilup de n sistem de traduziun automatica che funzionëia bun por le ladin dëida cherié poscibilités nöies da adoré le lingaz. Da öna na pert vëgn l'azes a chësc lingaz y ala cultura ladina scemplifiché, dal'atra pert vëgnel pité n stromënt che dëida cherié tesć y che pó ester de ütl por döta la comunité ladina. Al é porchël ince n contribut important por mantigní y por daidé crësce chësc lingaz, dantadöt tl monn digital.
Por de plü informaziuns: www.uibk.ac.at/de/theoretische-informatik/forschung/projekte/#MTladin
Maschinelle Übersetzung für die ladinische Sprache
Neue Möglichkeiten für die Verwendung und Erforschung der ladinischen Sprache schaffen.
In einem Kooperationsprojekt zwischen der Universität Innsbruck und dem ladinischen Kulturinstitut "Micurá de Rü" widmet sich unsere Forschung der Entwicklung eines innovativen maschinellen Übersetzungssystems, speziell für die ladinische Sprache. Ladinisch, auch als Dolomitenladinisch bekannt, ist eine in Italien offiziell anerkannte Minderheitensprache, die von rund 30.000 Menschen in den fünf Tälern rund um den Sellastock gesprochen wird.
Die ladinische Sprache zeichnet sich durch ihre einzigartige Diversität aus: Sie variiert signifikant von Tal zu Tal. Zu den Hauptvarianten zählen Val Badia (Gadertal), Val Gardena (Grödnertal), Fassa (Fassa), Ampezzo (Anpezo) und Buchenstein (Fodom). Diese Vielfalt stellt eine besondere Herausforderung dar, da jede Variante individuell behandelt werden muss.
Unser Ansatz ist es, zunächst die Variante des Gadertals in den Fokus zu nehmen. Wir entwickeln Methoden, die speziell für diese Variante konzipiert sind, mit dem Ziel, erfolgreiche Strategien später auf die anderen Varianten auszuweiten. Durch diese schrittweise Vorgehensweise streben wir danach, ein umfassendes und effizientes Übersetzungssystem zu schaffen, das die reiche kulturelle und sprachliche Vielfalt der ladinischen Sprache würdigt und fördert.
Breiterer Forschungskontext
Traditionell benötigen moderne Ansätze für die Entwicklung leistungsfähiger maschineller Übersetzungssysteme eine große Menge an Trainingsdaten. Die begrenzte Verfügbarkeit von Ressourcen und Texten in kleineren Sprachen verhindert jedoch eine effektive Anwendung dieser Algorithmen. In den letzten Jahren hat sich dieser Forschungsbereich verstärkt auf low-resource Szenarien und damit auch auf die maschinelle Übersetzung von weniger verbreiteten Sprachen konzentriert. Das hat zur Entwicklung verschiedener Methoden geführt, die das Problem der begrenzten Datenverfügbarkeit umgehen oder die verfügbaren Daten effizienter nutzen. Mit der Veröffentlichung von ChatGPT und anderen Large Language Models (LLMs) ist zudem ein völlig neuer Forschungszweig der maschinellen Übersetzung entstanden. LLMs verfügen als Sprachmodelle über ein beeindruckendes Verständnis für natürliche Sprache und können komplexe Kontexte verarbeiten. Darüber hinaus können sie mit wenigen Trainingsbeispielen auf neue Problemstellungen angepasst werden. Diese Fähigkeiten könnten in Kombination mit den entwickelten Methoden nun auch für die Weiterentwicklung der maschinellen Übersetzung für ressourcenarme Sprachen genutzt werden und den Weg zu gut funktionierenden Systemen auch in solchen Sprachen ebnen. Es bleibt die Frage, wie dies am besten gelingen kann.
Wirkung
Die erfolgreiche Entwicklung eines funktionsfähigen maschinellen Übersetzungssystems für Ladinisch würde neue Möglichkeiten für die Verwendung und Erforschung dieser Sprache schaffen. Auf der einen Seite könnte damit der Zugang zu dieser Sprache und Kultur erleichtert werden, auf der anderen Seite stünde ein wertvolles Werkzeug für das Erfassen ladinischer Texte zur Verfügung, das auch für die ladinische Gemeinschaft von Nutzen wäre. Somit wäre es auch ein wichtiger Beitrag zur Erhaltung dieser Sprache, zumindest in der digitalen Welt.
Weitere Informationen: www.uibk.ac.at/de/theoretische-informatik/forschung/projekte/#MTladin
Features / Funziuns
Dizionar
Clica sön na parora tl test da traslaté por la chirí sö tl dizionar y odëi traduziuns, formes, frases y sinonims.

- Dizionars: Ladin Val Badia - Italiano, Ladin Gherdëina - Italiano, Ladin Gherdëina - Deutsch
Traduziun alternatives
Odëi propostes alternatives por parores tl test de traduziun.
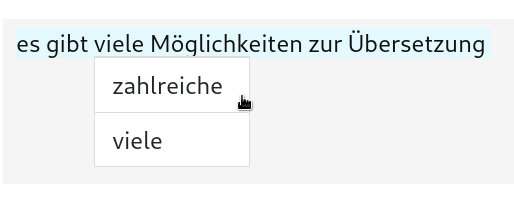
- Clica sön na parora tl test traslatè por odëi alternatives
- Chir fora na proposta che passenëia tl contest.
Traduziun asvëlta cun GPU
Le sistem de traduziun mëss fá n gröm de cunc por fá la traduziun. Chisc pó gni fac cotan plü debota sön GPU.
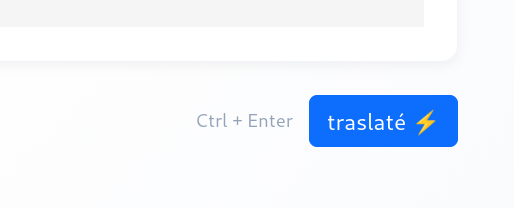
- Traduziuns plü asvëltes por tesć plü lunc
- An vëiga na saita ⚡ tl botun "traslaté" sce la traduziun é gnüda fata cun GPU
- Al n'é nia tresfora na GPU a desposiziun
Coretur ortografich
Identificaziun y propostes de coreziun por fai de batüda ti tesc ladins.
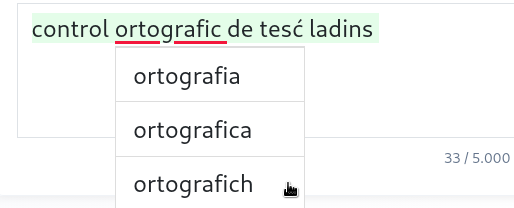
- Parores nia reconüdes vëgn sotrissades a cöce
- Clica sön na parora sotrissada por odëi propostes de coreziun
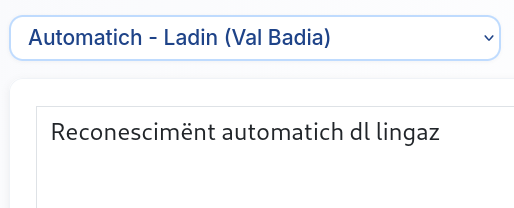
Reconescimënt automatich dl lingaz
Le sistem reconësc automaticamënter le lingaz dl test da traslaté.
Shortcuts / Cörtes
Adoré le tradutur cun cörtes.
Generales
- Ctrl + ↵ Traslaté
- Ctrl + K Copié la traduziun
- Ctrl + R Reseté
- Ctrl + S Müdé direziun
Sëgns speziai
- Alt + A/E/I/O/U ä/ë/ï/ö/ü
- Alt + Shift + A/E/I/O/U Ä/Ë/Ï/Ö/Ü